R言語と統計学を同時に学ぶことができる『Rによるやさしい統計学』を少しずつ読み進めています。
この本は難しい数学の式などは出てこずに、わかりやすい言葉や例で統計学の基礎的なキーワードとそれに紐づく「Rの使い方」に焦点を当て、説明をしてくれています。個人的には事前に基本的な概念を説明した入門書を一冊やってから、「Rではどうやるか?」を知るにオススメな本だと思います。
まだ前半戦の状態ですが、この中で特に覚えておきたい部分を中心にメモを書いていきます。
🐠 2章: 1つの変数の記述統計
データ解析の出発点となる『1つの変数』の記述方法についての説明。
😀 レクチャー
# c: データの値を結合させる |
例題やってみた
a <- c(60,100,50,40,50,230,120,240,200,30)< span> |
hist(b) |
# 2) |
🐰 3章: 2つの変数の記述統計
『2つの変数における量的変数における関係、質的変数における関係』についての説明です。ちなみに量的変数と質的変数の説明は次のとおり。
😸 レクチャー
* 量的変数: データ間に優劣や大小が比較できる。『テストの点数』のような数値データ => 比率データ: 絶対的なゼロ点を有する(質量、長さ、年齢、時間、金額など) => 間隔データ: 数値(メモリ)の間隔が等しい(気温、知能指数など) * 質的変数: データ間に優劣がなく、大小関係が比較できない。「男・女」や「好き・嫌い」など => 順序データ: 大小関係(順序)のみ意味をもつ(満足度、選好度、硬度など) => 名義データ: 内容を区別するために便宜的に割りあている(電話番号、性別など)
さらに、相関(correlation)と回帰(regression)の説明は次のとおり。
相関 correlation #=> xとyの間に区別をもうけず対等に見る見方や方法 回帰 regression #=> xからyを見る(yからxを見る)方法
# 分散図(グラフの表示) |
# 共分散(数値) |
相関係数は-1 <= r <="1で次のように関係性がわかります。
-0.2 <= r <="0.2" #> ほとんど相関なし -0.4 <= r < -0.2, 0.2 #> 弱い相関あり -0.7 <= r < 0.4, 0.4 #> 中程度の相関あり -1.0 <= r < -0.7, 0.7 #> 強い相関あり
# クロス集計表 |
例題やってみた
# 1) 散布図 |
# 2) 相関係数 |
Rの便利メソッド
# Rのメソッド |
🎂 第4章: 母集団と標本
大きな集団(母集団)から取り出した少数のデータ(標本)を使って『もとの集団の性質について推測する』ための推測統計の基本的な理論についての学習。
母集団と標本の説明はこちら。
母集団: データ全体を指す。国民全体、工業製品全体など 標本: 母集団から取り出したデータの一部
推測統計の分類についてはこちら。
推定: 具体的な数値を用いて『母数の値は◯◯くらいだろう』という結論を導くこと 点推定: 1つの値で空いての結果を表す。日本の中学生の数学平均点が「60点」と推定 区間推定: ある程度の幅を持った区間で結果を表す。数学平均が『50-70点』と推定
## サイコロを6回ふった場合、サイコロのすべての目が1回ずつ出るのは稀 |

# 正規分布 |
# 母集団が正規分布であるような集団から無作為標本を抽出 |
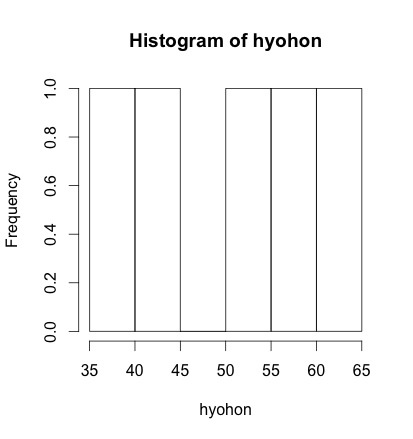
上のように標本数が少ないと、正規分布かどうかはわかりません。ただし、サンプルサイズをある程度大きくするとヒストグラムは正規分布に近いものになっていきます。
# 標本数を増やした場合のヒストグラム => 正規分布に近づく |
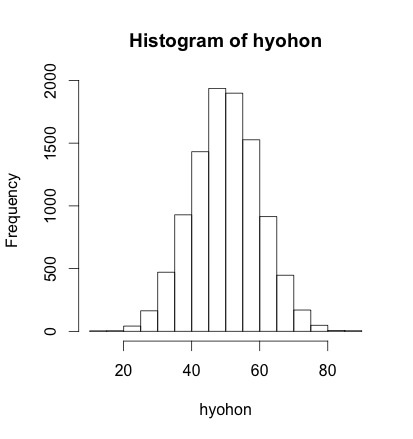
練習問題をやってみた
# 1) 経験的な標本分布 |
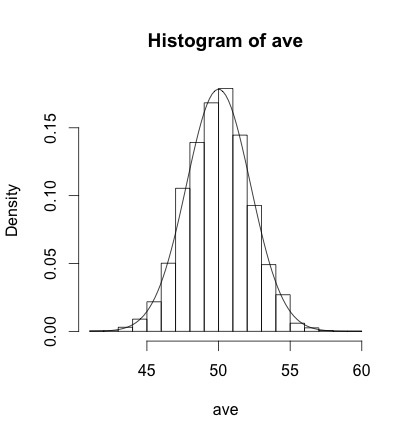
# 2) 理論的な標本分布 |
本章で出てくるRの関数
# 小数点以下の切り上げ |
🎉 第5章: 統計的仮説検定
検定の手順
1) 母集団に関する帰無仮説と対立仮説を設定する 2) 検定統計量を選ぶ 3) 有意水準αの値を決める 4) データから検定統計量の実現値を求める 5) 検定統計量の実現値が棄却域に入る => 対立仮説を採用する
検定のキーワード
帰無仮説 #=>「差がない」、「効果が無い」という仮説 対立仮説 #=> 帰無仮説に反して「差がある」という仮説 検定統計量 #=> 検定に用いられる標本統計量のこと 有意水準 #=> 帰無仮説を棄却し対立仮説を採択する基準 棄却域 #=> 非常に生じにくい検定統計量の値の範囲 p値 #=> 帰無仮説が正しい仮説で、標本から計算した検定統計量を実現できる確率 第1種の誤り #=> 「帰無仮説が真の時にこれを棄却する」誤り 第2種の誤り #=> 「帰無仮説が偽の時にこれを採択する」誤り 検定力 #=> 間違っている仮説を正しく棄却できる確率のこと(100% - 第2種の誤りの確率)
標準正規分布を用いた検定の例題をやってみた
# 標準正規分布を用いた検定の検定統計量 : Z = mean(x) - 標準正規分布の平均/sqrt(標準正規分布の分散/標本数)
sinri <- c(13, 14, 7, 12, 10, 6, 8, 15, 4, 9, 5, 15)< span> |
t分布を用いた検定の例題をやってみた
先述の「標準正規分布を用いた検定」は母集団の分散が計算に必須です。そこで、未知の母集団の分散の代わりに、自由度(データの標本数 - 1)のt分布を元に計算する検定があります。
# t分布を用いた検定の検定統計量 : t = (mean(x) - 母集団の平均)/sqrt(t分布の分散/標本数)
# 5.4 例題 |
無相関検定の例題をやってみた
母集団において相関が0であることを検定するための手法。
# t分布を用いた検定の検定統計量 : t = (標本相関 * sqrt(標本数 - 2))/sqrt(1 - 標本相関)
## 帰無仮説 => toukei1とtoukei2の相関係数は0である |
独立性の検定(χ2乗検定)の例題をやってみた
## 帰無仮説 => 「数学の好き嫌い」と「統計の好き嫌い」には差がない |
練習問題をやってみた
## 1) |
便利なRの関数
# 標準正規分布の下側確率に対応する値 |
🖥 VULTRおすすめ
「VULTR」はVPSサーバのサービスです。日本にリージョンがあり、最安は512MBで2.5ドル/月($0.004/時間)で借りることができます。4GBメモリでも月20ドルです。 最近はVULTRのヘビーユーザーになので、「ここ」から会員登録してもらえるとサービス開発が捗ります!

📚 おすすめの書籍









