この本のシリーズ本の『統計学がわかる』がすごくわかりやすかったので、その続きの本『統計学がわかる 回帰分析・因子分析編』を読みました。
こちらの本もアイスクリーム屋さんの店長と店員を軸に、テンポよく回帰分析を中心に勉強することができます。この本の中で特に参考になった点をピックアップしてマトメていきます!
🎃 第1章:散布図と相関
ポイント
* 散布図はデータの散らばり具合やデータ同士の関係を表す * 散布図には、正の相関、負の相関、無相関のパターンがある
確認テスト
# 2) 散布図 |
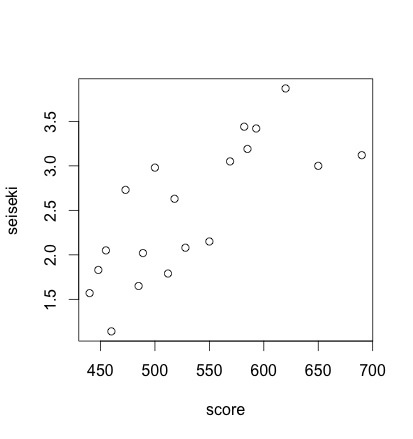
# 3) 散布図から読み取れること |
👽 第2章:相関係数
ポイント
相関係数 = 偏差席の平均 / (標準偏差X*標準偏差Y)
確認テスト
# 1) 相関係数 |
🐰 第3章:無相関検定
確認テスト
# 1) 無作為抽出された場合どのようなことが言えるか? |
😸 第4章:回帰直線
ポイント
データとの差(残差)が最小となるところに引いた線を「回帰直線」と呼ぶ 回帰直線の傾き = 相関係数 * (yの標準偏差/xの標準偏差) 回帰直線のy切片 = yの平均 - (傾き*xの平均) 回帰直線はデータを推測するのに利用される
確認テスト
score <- c(440, 448, 455, 460, 473, 485, 489, 500, 512, 518, 528, 550, 582, 569, 585, 593, 620, 650, 690)< span> |
🚜 第5章: 偏相関
ポイント
偏相関 => 変数a, b, yが3つあるとき、変数bと変数yの相関から変数aの影響を取り除いたもの 偏相関係数 => (r_by - (r_ay * r_ab))/(sqrt(1-r_ay^2)*sqrt(1-r_ab^2)) 偏相関を言い換えると => 第三の変数との残差同士の相関
確認テスト
# 第5章 |
参考リンク
🍮 第6章:重回帰
ポイント
偏回帰係数 => 偏相関の回帰直線の傾き 単回帰 => 1つの説明変数で独立変数(別の変数)を予測するモデル 重回帰 => 2つ以上の説明変数で独立変数(別の変数)を予測するモデル 重相関係数 => 実測値と重回帰モデルによる予測値の相関関係
確認テスト
score <- c(440, 448, 455, 460, 473, 485, 489, 500, 512, 518, 528, 550, 582, 569, 585, 593, 620, 650, 690)< span> |
Speical Thanks
🏀 第7章:多変量データ
ポイント
多変量データ => 沢山のデータからなる変数 相関行列 => 変数どう押しの相関係数を整理した表
🚕 第8章:因子分析
因子分析 => 多変量データを分析する手法の一つ。多くの観測変数を分析することで、観測変数に影響をあたえる共通要因を求める 因子負荷 => 観測変数に対して共通因子がどれくらいの強さで影響をあたえるかを示したもの 因子得点 => それぞれのケースが、各因子に対してどれくらいの重みを持っているかを計算したもの
🐮 お勧めサイト
R による統計処理
いろんな統計入門系のサイトを見ていると、かなり評判がいいのがこちらのサイト。少しずつこなしたい!
データセット一覧 : DoDStat@d
より複雑なデータ・セットがあるので、いろんな解析の勉強をするときに使ってみたい。
🖥 VULTRおすすめ
「VULTR」はVPSサーバのサービスです。日本にリージョンがあり、最安は512MBで2.5ドル/月($0.004/時間)で借りることができます。4GBメモリでも月20ドルです。 最近はVULTRのヘビーユーザーになので、「ここ」から会員登録してもらえるとサービス開発が捗ります!

📚 おすすめの書籍









